2025

Offload Rethinking by Cloud Assistance for Efficient Environmental Sound Recognition on LPWANs
Le Zhang*, Quanling Zhao*, Run Wang, Shirley Bian, Onat Gungor, Flavio Ponzina, Tajana Rosing (* equal contribution)
the ACM Conference on Embedded Networked Sensor Systems (SenSys) 2025
We present ORCA, a resource-efficient, cloud-assisted environmental sound recognition system designed for batteryless devices using Low-Power Wide-Area Networks (LPWANs). ORCA addresses the accuracy limitations of on-device methods and reduces communication costs of cloud-offloading strategies, enabling ultra-low-power, wide-area audio sensing applications.
Offload Rethinking by Cloud Assistance for Efficient Environmental Sound Recognition on LPWANs
Le Zhang*, Quanling Zhao*, Run Wang, Shirley Bian, Onat Gungor, Flavio Ponzina, Tajana Rosing (* equal contribution)
the ACM Conference on Embedded Networked Sensor Systems (SenSys) 2025
We present ORCA, a resource-efficient, cloud-assisted environmental sound recognition system designed for batteryless devices using Low-Power Wide-Area Networks (LPWANs). ORCA addresses the accuracy limitations of on-device methods and reduces communication costs of cloud-offloading strategies, enabling ultra-low-power, wide-area audio sensing applications.
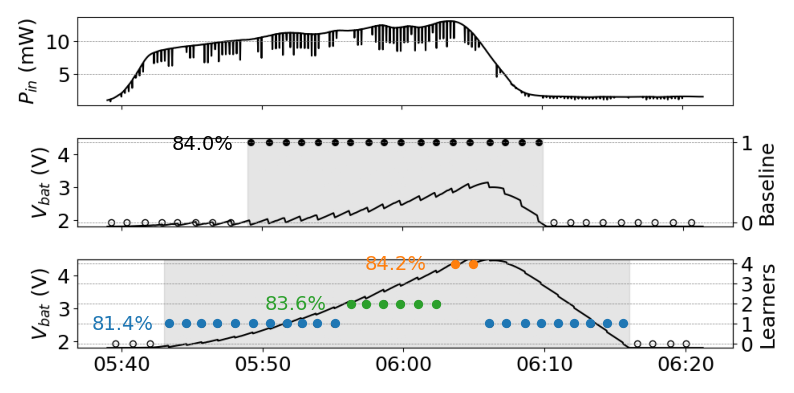
E-QUARTIC: Energy Efficient Edge Ensemble of Convolutional Neural Networks for Resource-Optimized Learning
Le Zhang, Onat Gungor, Flavio Ponzina, Tajana Rosing
Asia and South Pacific Design Automation Conference (ASPDAC) 2025
We propose E-QUARTIC, an energy-efficient edge ensembling framework that constructs CNN ensembles optimized for AI-based embedded systems, achieving higher accuracy than single-instance CNNs and existing edge solutions without additional memory overhead. Leveraging its multi-CNN architecture, E-QUARTIC also implements an energy-aware model selection strategy tailored for energy-harvesting AI environments.
E-QUARTIC: Energy Efficient Edge Ensemble of Convolutional Neural Networks for Resource-Optimized Learning
Le Zhang, Onat Gungor, Flavio Ponzina, Tajana Rosing
Asia and South Pacific Design Automation Conference (ASPDAC) 2025
We propose E-QUARTIC, an energy-efficient edge ensembling framework that constructs CNN ensembles optimized for AI-based embedded systems, achieving higher accuracy than single-instance CNNs and existing edge solutions without additional memory overhead. Leveraging its multi-CNN architecture, E-QUARTIC also implements an energy-aware model selection strategy tailored for energy-harvesting AI environments.
2024
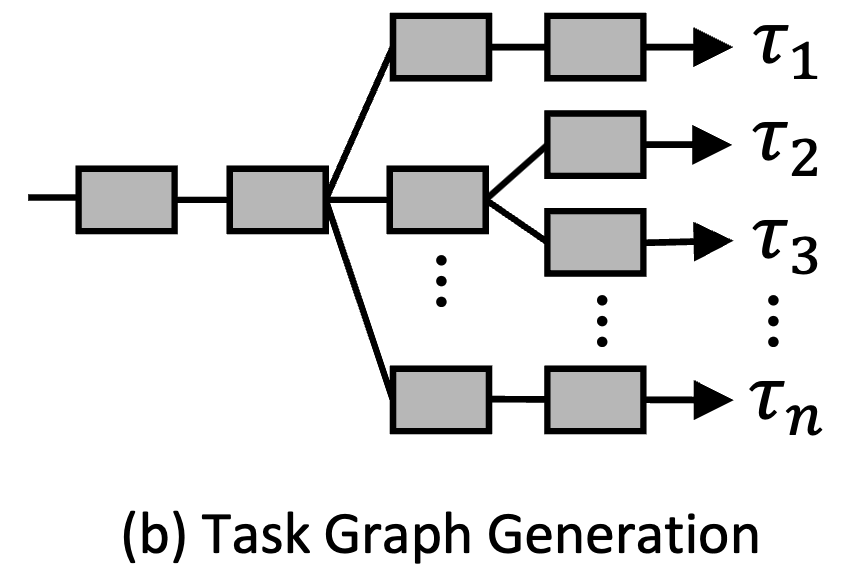
Efficient Multitask Learning on Resource-constrained Systems
Yubo Luo, Le Zhang, Zhenyu Wang, Shahriar Nirjon
International Conference on Embedded Wireless Systems and Networks (EWSN) 2024
We introduce Antler, a multitask inference system that constructs a compact task graph by exploiting task affinities, optimizing the execution order to significantly reduce end-to-end inference time and energy usage. Antler leverages overlaps and dependencies among tasks to avoid redundant computations while maintaining accuracy comparable to state-of-the-art approaches.
Efficient Multitask Learning on Resource-constrained Systems
Yubo Luo, Le Zhang, Zhenyu Wang, Shahriar Nirjon
International Conference on Embedded Wireless Systems and Networks (EWSN) 2024
We introduce Antler, a multitask inference system that constructs a compact task graph by exploiting task affinities, optimizing the execution order to significantly reduce end-to-end inference time and energy usage. Antler leverages overlaps and dependencies among tasks to avoid redundant computations while maintaining accuracy comparable to state-of-the-art approaches.
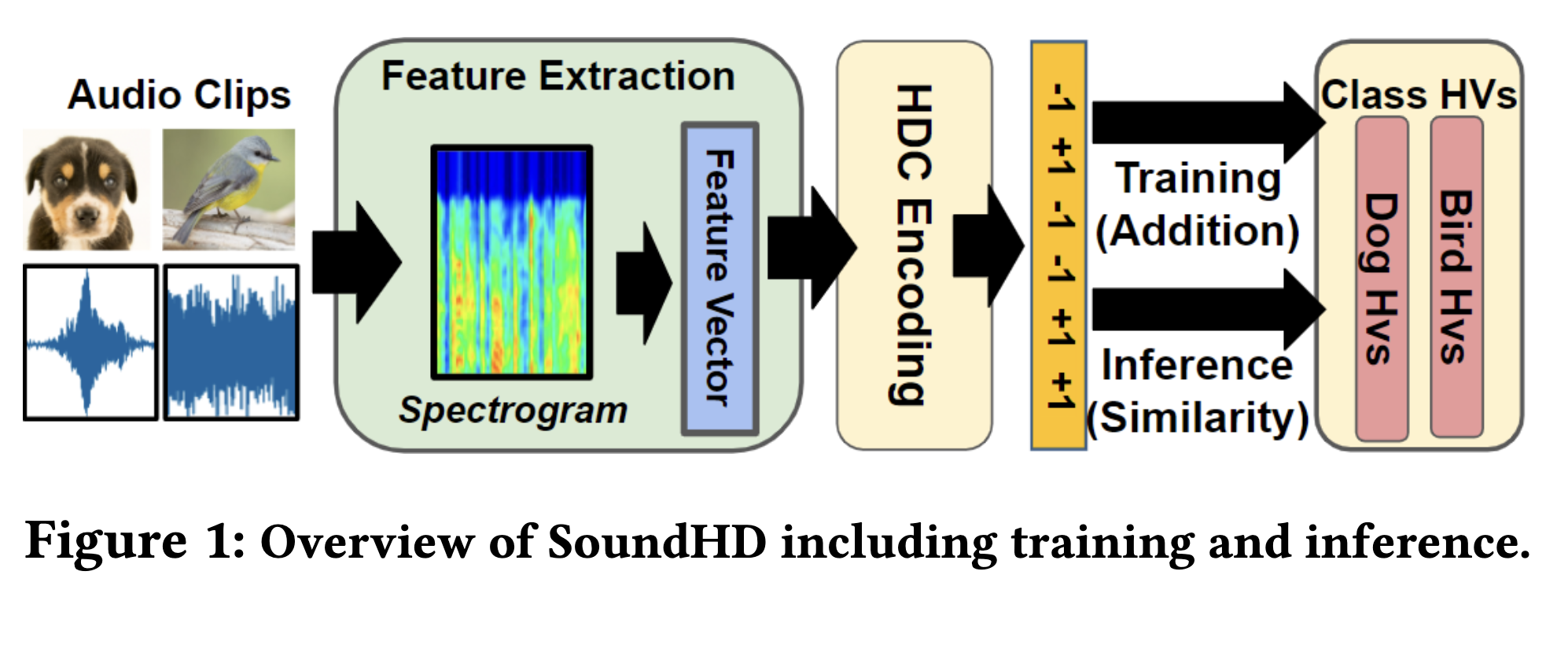
Poster: Resource-Efficient Environmental Sound Classification Using Hyperdimensional Computing
Run Wang, Shirley Bian, Xiaofan Yu, Quanling Zhao, Le Zhang, Tajana Rosing
ACM Conference on Embedded Networked Sensor Systems (SenSys) 2024
We introduce SoundHD, an on-device environmental sound classification (ESC) system utilizing Hyperdimensional Computing (HDC), a lightweight, brain-inspired computing paradigm. SoundHD addresses resource efficiency challenges, enabling practical ESC deployment on constrained edge devices such as microcontrollers in rural environments.
Poster: Resource-Efficient Environmental Sound Classification Using Hyperdimensional Computing
Run Wang, Shirley Bian, Xiaofan Yu, Quanling Zhao, Le Zhang, Tajana Rosing
ACM Conference on Embedded Networked Sensor Systems (SenSys) 2024
We introduce SoundHD, an on-device environmental sound classification (ESC) system utilizing Hyperdimensional Computing (HDC), a lightweight, brain-inspired computing paradigm. SoundHD addresses resource efficiency challenges, enabling practical ESC deployment on constrained edge devices such as microcontrollers in rural environments.
2022
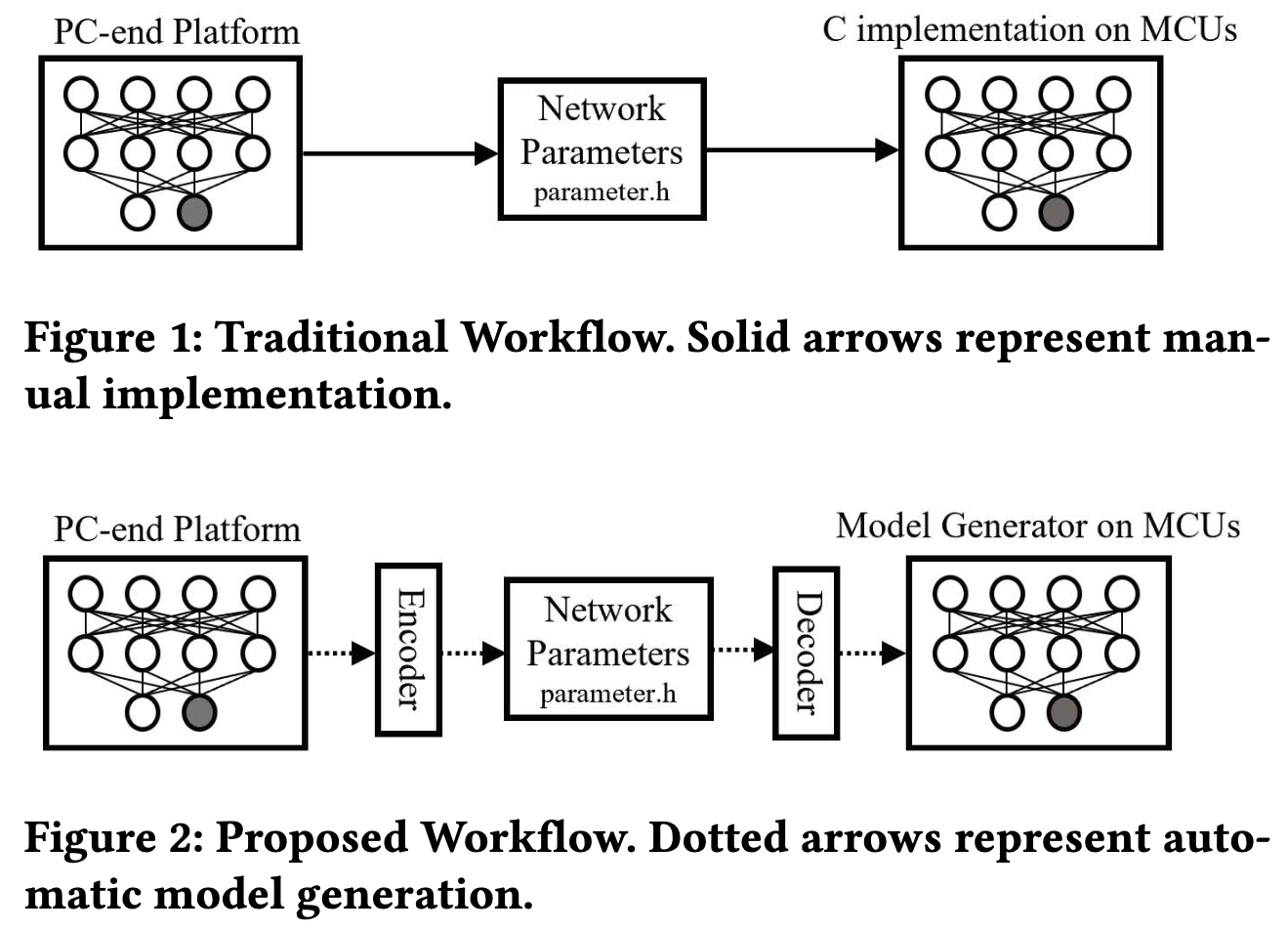
Demo Abstract: Capuchin: A Neural Network Model Generator for 16-bit Microcontrollers
Le Zhang, Yubo Luo, Shahriar Nirjon
ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN) 2022
We present a neural network model generator that automatically transfers parameters from pre-trained DNN or CNN models to 16-bit microcontrollers and implements on-device inference. This tool bridges the gap in efficiency and usability between development tools for 16-bit and 32-bit microcontrollers, significantly simplifying deep learning deployment on ultra-low-power devices.
Demo Abstract: Capuchin: A Neural Network Model Generator for 16-bit Microcontrollers
Le Zhang, Yubo Luo, Shahriar Nirjon
ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN) 2022
We present a neural network model generator that automatically transfers parameters from pre-trained DNN or CNN models to 16-bit microcontrollers and implements on-device inference. This tool bridges the gap in efficiency and usability between development tools for 16-bit and 32-bit microcontrollers, significantly simplifying deep learning deployment on ultra-low-power devices.